
탁구, 팬케이크, 벽돌 깨기
머신러닝 강화학습은 학습에 ‘보상(Reward)’을 이용합니다. 사리사욕이 없는 인공지능을 대상으로 보상을 통해 학습시킨다는 말이 쉽게 이해되지 않을 것입니다. 인공지능에게 제공하는 보상은 사람의 기준과는 차이가 있습니다. 여기서는 인공지능에게 ‘탁구’, ‘팬케이크 뒤집기’, ‘벽돌 깨기’를 학습시키는 사례를 이용해 강화학습에 대해 알아보겠습니다.
머신러닝을 활용하기 전, 탁구를 하는 로봇을 만들기 위해서는 모든 경우의 수에 대한 움직임을 명확하게 프로그램으로 작성해야만 했습니다. ‘공이 어떤 각도에서 어떤 속도로 올 때는 로봇이 어떻게 팔을 움직여 어떤 속도로 공을 치라.’는 식으로 말이죠. 하지만 이를 프로그래밍하는 것은 거의 불가능에 가까웠습니다. 탁구를 하면서 발생할 수 있는 모든 경우의 수를 나열하기도 쉽지 않고 그 모든 경우의 수에 대응하는 방법을 명확하게 알려 주는 것도 불가능했죠. 그래서 스스로 학습할 수 있는 머신러닝을 활용했습니다.
로봇에게 탁구를 가르칠 때는 먼저 사람이 로봇의 팔로 탁구공을 어떻게 치는지 가르칩니다. 실제로 사람이 로봇의 팔을 들고 탁구를 치며 로봇에게 탁구를 가르치는 것입니다. 다음은 사람이 로봇의 팔로 공을 치며 탁구를 가르치고 이렇게 탁구를 학습한 로봇과 사람이 탁구 대결을 하는 장면입니다.
강화학습 탁구 예시 ①


로봇은 사람에게 배운 여러 가지 기본 동작을 기억한 후 이 동작을 가중치별로 조합해 어떻게 공을 칠 것인지 결정합니다. 이때 로봇이 공을 잘 치면 보상을 높여 주고 공을 못 치면 보상을 주지 않거나 줄이는 방법으로 강화합니다. 여기서 보상은 게임의 점수와 같습니다. 공을 잘 치면 점수를 높여 주고 잘 치지 못하면 점수를 주지 않거나 낮추면서 로봇이 높은 점수를 받는 쪽으로 행동을 강화하도록 유도합니다. 로봇은 계속 탁구를 치면서 높은 점수를 얻을 수 있도록 행동의 알고리즘을 수정하고 점점 탁구를 잘 치게 되는 것이죠.
강화학습 탁구 예시 ②


로봇에게 팬케이크를 뒤집는 방법을 가르치는 것도 이와 똑같은 원리입니다. 먼저 사람이 로봇의 팔로 팬케이크를 뒤집으며 방법을 학습시킨 후 로봇이 이를 바탕으로 팬케이크 뒤집기를 학습합니다. 이 과정에서도 많은 보상(점수)을 얻기 위해 노력하다 보면 로봇은 점점 팬케이크를 잘 뒤집게 되죠.
강화학습 팬케이크 뒤집기 예시


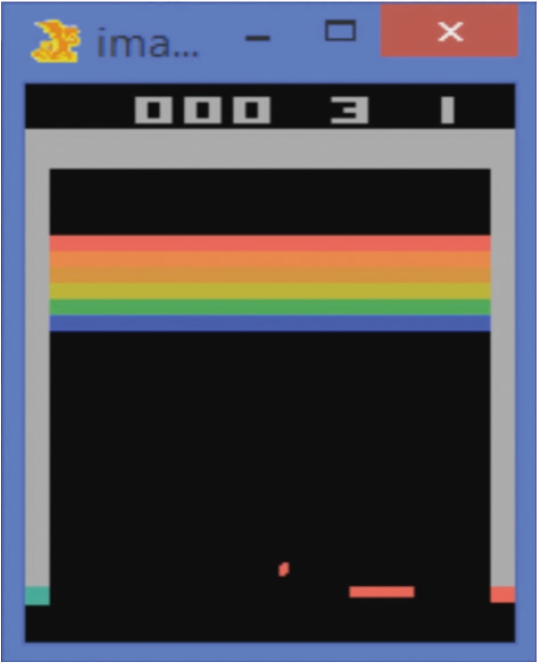
다음으로 살펴볼 사례는 ‘벽돌 깨기’ 게임입니다. 탁구와 팬케이크 뒤집기는 사람이 직접 로봇을 학습시켰지만, 벽돌 깨기 게임은 사람이 아무것도 가르쳐 주지 않고 규칙만 알려 준 상태에서 인공지능 스스로 높은 점수를 얻기 위한 방법을 터득합니다. 계속 스스로 게임을 하면서 높은 보상(점수)을 얻기 위한 방법을 찾는 것이죠.
강화학습 벽돌깨기 예시

이세돌 9단과 대결한 알파고도 강화학습을 이용했습니다. 알파고는 프로 바둑기사들의 바둑을 학습한 후 스스로 자체 대결을 통해 경기를 합니다. 이때 최종적으로 승리하는 쪽이 보상을 받게 되며, 보상을 더 받는 방향, 즉 이기는 방향으로 알고리즘의 가중치를 수정했습니다. 이를 위해 알파고는 바둑 돌을 놓을 위치를 결정하는 ‘정책 네트워크(Policy Network)’와 게임에서 이길 가능성, 즉 승률을 계산하는 ‘가치 네트워크(Value Network)’로 구성됩니다. 알파고를 만든 딥마인드에서 2015년에 발표한 논문에 따르면, 강화학습을 통해 전통적인 게임을 하는 프로그램을 만들었는데, 테스트한 49개 게임 중 29개 게임에서 사람보다 높은 점수를 얻었습니다.
'과학·공학 > <AI 상식사전>' 카테고리의 다른 글
| 06. 인공신경망예시 _자율주행차 (마지막 회) (1) | 2022.07.15 |
|---|---|
| 04. 머신러닝이란? _머신러닝과 전통적인 프로그램의 차이 (1) | 2022.07.13 |
| 03. 고인을 되살리는 인공지능 _불쾌한 골짜기 (2) | 2022.07.12 |
| 02. 인공지능 기술 발전에 따른 변화 _사라지는 일자리, 생기는 일자리 (0) | 2022.07.10 |
| 01. 이미 내 삶 속에 들어온 인공지능 _인공지능 활용 사례 (1) | 2022.07.08 |




댓글